Лекция: Введение в GPU-вычисления
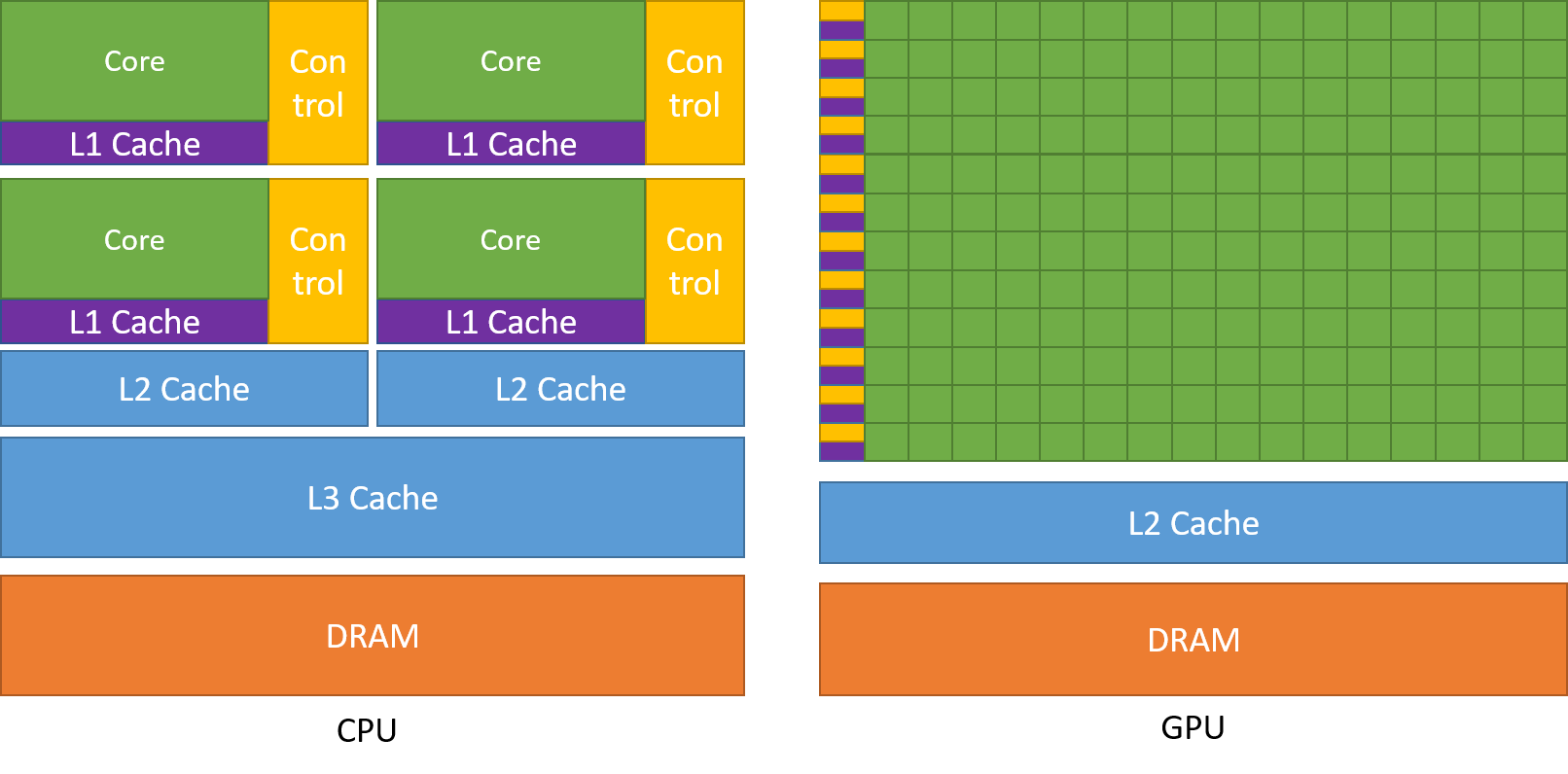
Общая архитектура GPU
Основные компоненты GPU
- Графические процессоры (Streaming Multiprocessors, SMs): Основные вычислительные блоки GPU. Содержат множество ядер, которые работают параллельно.
- Ядра CUDA (CUDA Cores): Простые арифметические блоки внутри SMs. В каждом SM сотни ядер CUDA.
- Блочная архитектура: GPU организованы в блоки (warps), состоящие из 32 потоков, которые выполняют инструкции одновременно.
- Унифицированная память: Общая память между CPU и GPU, позволяющая обмениваться данными.
Отличия от CPU
- Массивно-параллельные вычисления: GPU оптимизированы для выполнения тысяч потоков одновременно, в отличие от CPU, которые фокусируются на выполнении нескольких мощных потоков.
- Простые ядра: Ядра CUDA проще и легче, чем ядра CPU, что позволяет их интеграцию в больших количествах.
Подход к программированию GPU на примере CUDA
Основные концепции CUDA
- Ядро (Kernel): Функция, выполняемая на GPU. Определяется с помощью ключевого слова
__global__. - Потоки и блоки: Ядра выполняются параллельно в рамках потоков, организованных в блоки.
- Глобальная, локальная и общая память: Разные типы памяти с различной скоростью доступа и размером.
Пример простейшей программы на CUDA
#include <iostream>
#include <cuda_runtime.h>
__global__ void addKernel(int* c, const int* a, const int* b, int size) {
int i = threadIdx.x + blockIdx.x * blockDim.x;
if (i < size) {
int sum = a[i] + b[i];
if (sum > 30) {
c[i] = sum;
}
}
}
int main() {
const int arraySize = 5;
const int a[arraySize] = {1, 2, 3, 4, 5};
const int b[arraySize] = {10, 20, 30, 40, 50};
int c[arraySize] = {0};
int* dev_a = nullptr;
int* dev_b = nullptr;
int* dev_c = nullptr;
cudaMalloc((void**)&dev_a, arraySize * sizeof(int));
cudaMalloc((void**)&dev_b, arraySize * sizeof(int));
cudaMalloc((void**)&dev_c, arraySize * sizeof(int));
cudaMemcpy(dev_a, a, arraySize * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, arraySize * sizeof(int), cudaMemcpyHostToDevice);
addKernel<<<1, arraySize>>>(dev_c, dev_a, dev_b, arraySize);
cudaMemcpy(c, dev_c, arraySize * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < arraySize; ++i) {
std::cout << c[i] << " ";
}
std::cout << std::endl;
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
PTX (Parallel Thread Execution)
PTX (Parallel Thread Execution) — это ISA, разработанный NVIDIA для параллельного исполнения потоков на их GPU. PTX является промежуточным представлением, которое используется при компиляции кода CUDA.
Основные аспекты PTX
-
Промежуточное представление:
- PTX генерируется компилятором
nvccиз исходного кода CUDA. - Он не выполняется непосредственно на GPU, а служит промежуточным шагом перед финальной компиляцией в машинный код (SASS — Streaming Assembler), специфичный для архитектуры целевого GPU.
- PTX генерируется компилятором
-
Архитектурная независимость:
- PTX код является независимым от конкретной архитектуры GPU, что позволяет ему быть перенесенным и использованным на различных поколениях GPU с минимальными изменениями.
-
Компиляция Just-In-Time (JIT):
- Во время выполнения CUDA-драйвер компилирует PTX в SASS, обеспечивая оптимальную производительность на целевой архитектуре GPU.
PTX играет важную роль в экосистеме CUDA, служа промежуточным представлением между исходным кодом CUDA и исполняемым машинным кодом на GPU. Он обеспечивает архитектурную независимость, оптимизацию производительности и гибкость в разработке параллельных программ.
Единая память (Unified Memory)
Единая память в CUDA — это система управления памятью, которая предоставляет единое адресное пространство, доступное как для CPU, так и для GPU. Она упрощает управление памятью, позволяя выделять данные один раз и автоматически мигрировать их между хостом (CPU) и устройством (GPU) по мере необходимости.
Основные особенности единой памяти
- Единое адресное пространство: CPU и GPU разделяют одно и то же адресное пространство, что упрощает управление указателями и структурами данных.
- Автоматическая миграция данных: Среда выполнения CUDA автоматически управляет миграцией данных между хостом и устройством в зависимости от того, где данные используются.
- Упрощение кода: Разработчикам не нужно явно управлять передачей памяти между хостом и устройством, что снижает сложность кода.
Использование единой памяти в примере
В предыдущем примере мы не использовали единую память. Вместо этого мы использовали явные функции управления памятью, такие как cudaMalloc, cudaMemcpy и cudaFree, чтобы выделить, передать и освободить память между хостом и устройством.
Вместо этого мы могли бы использовать единую память, что упростило бы управление памятью и устранило необходимость в явных вызовах функций передачи данных. Пример использования единой памяти можно найти в файле unified.cu.
// Allocate Unified Memory – accessible from both CPU and GPU
checkCudaError(cudaMallocManaged(&dev_a, arraySize * sizeof(int)), "cudaMallocManaged failed for dev_a");
checkCudaError(cudaMallocManaged(&dev_b, arraySize * sizeof(int)), "cudaMallocManaged failed for dev_b");
checkCudaError(cudaMallocManaged(&dev_c, arraySize * sizeof(int)), "cudaMallocManaged failed for dev_c");
// Copy data from host to Unified Memory
memcpy(dev_a, a, arraySize * sizeof(int));
memcpy(dev_b, b, arraySize * sizeof(int));
// Launch kernel
addKernel<<<1, arraySize>>>(dev_c, dev_a, dev_b, arraySize);
// Wait for GPU to finish before accessing on host
checkCudaError(cudaDeviceSynchronize(), "cudaDeviceSynchronize failed");
// Print the result
std::cout << "Result: ";
for (int i = 0; i < arraySize; ++i) {
std::cout << dev_c[i] << " ";
}
std::cout << std::endl;
Преимущества использования единой памяти
- Упрощенное управление памятью: Разработчикам не нужно явно управлять передачей памяти между хостом и устройством, что снижает риск ошибок и упрощает код.
- Легкость использования: Единая память особенно полезна для начинающих или для приложений, где простота использования важнее, чем оптимизация производительности.
- Автоматическая согласованность данных: Среда выполнения CUDA обеспечивает использование самой последней копии данных, поддерживая согласованность данных между хостом и устройством.
Производительность
Хотя единая память упрощает управление памятью, она может привести к снижению производительности из-за автоматической миграции данных. Для критически важных приложений по производительности может быть предпочтительно использовать явное управление памятью для оптимизации передачи данных и использования памяти.
Ветвление и маскирование в CUDA
- Предикаты и маскирование: В CUDA используется предикация для управления выполнением инструкций в потоке. Если условие не выполняется, инструкции для этих потоков становятся no-op.
- Управление ветвлением: При ветвлении, разные пути выполнения в потоке выполняются последовательно с использованием предикатов.
Сравнение AVX и CUDA
Ветвление и маскирование в AVX
- Маскированные инструкции: В AVX используются маскированные инструкции для выполнения операций над частями данных, позволяя условное выполнение операций.
- Пример кода на AVX:
void add_avx(const int* a, const int* b, int* c, int size) {
__m256i vec_a, vec_b, vec_sum, vec_mask;
for (int i = 0; i < size; i += 8) {
vec_a = _mm256_loadu_si256((__m256i*)&a[i]);
vec_b = _mm256_loadu_si256((__m256i*)&b[i]);
vec_sum = _mm256_add_epi32(vec_a, vec_b);
vec_mask = _mm256_cmpgt_epi32(vec_sum, _mm256_set1_epi32(30));
vec_sum = _mm256_blendv_epi8(_mm256_setzero_si256(), vec_sum, vec_mask);
_mm256_storeu_si256((__m256i*)&c[i], vec_sum);
}
}
Пример кода на CUDA:
__global__ void addKernel(int* c, const int* a, const int* b, int size) {
int i = threadIdx.x + blockIdx.x * blockDim.x;
if (i < size) {
int sum = a[i] + b[i];
if (sum > 30) {
c[i] = sum;
}
}
}
Сравнение подходов
- AVX: Использует маскированные инструкции для выполнения операций над векторными регистрами. Ветвление осуществляется с использованием масок, которые определяют, какие элементы участвуют в вычислениях.
- CUDA: Использует предикаты и последовательное выполнение различных путей в потоке. Ветвление в потоке может приводить к снижению производительности из-за последовательного выполнения.
Заключение
GPU-вычисления предлагают мощный инструмент для параллельной обработки данных, особенно в задачах, требующих массивно-параллельных вычислений. CUDA предоставляет удобный и мощный способ программирования GPU, но требует понимания специфики архитектуры и управления параллелизмом.